
我走向你像走向一条河流
Joined May 2022
铜仁女啊!啊!
boosted

铜仁女啊!啊!
boosted

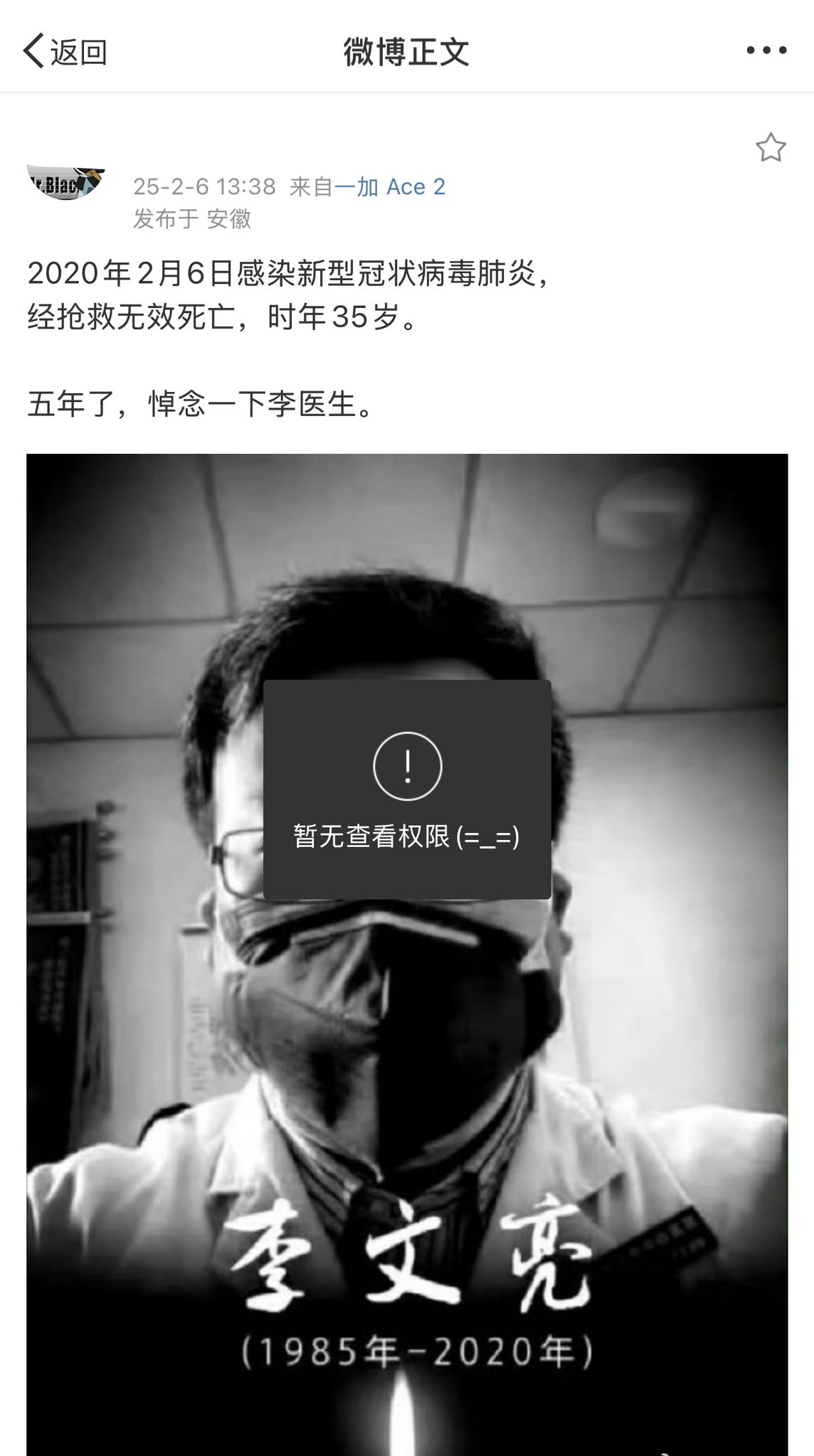
昨天看了个ytb上的长视频,也是访谈类的视频,一看制作者就有专业背景,采访一个在国内因为某些事犯罪后入狱,出来因为自己的犯罪标签找不到工作,九年来连最底层的打工都频繁被开除被拒绝的讲述者。
这是个多么好的机会探讨中国的所谓法治环境,质问对犯罪者回归社会的种种保障机制的缺失,质问对个人隐私的无底线滥用,造成今天这样一个“一旦犯罪,永不翻身”的人权环境,这是每个人的危机。
然而这视频的最后,被采访者说我想告诉大家中国的犯罪成本有多高,我想让自己的现身说法,来劝人向善不要犯罪。把我恶心坏了。
果然审查机制下的内容生产或者自媒体,全都是垃圾,视频做得越精良越垃圾。
铜仁女啊!啊!
boosted

看过 幕府将军 🌕🌕🌕🌕🌑
好看,里面的女角色都很亮眼…………着实是一部非常日本但是一看就不是日本本土拍的剧,虽然不免还是有一些白人中心视角的傲慢感但总体来说非常不错了,真的很日本
铜仁女啊!啊!
boosted

有时候国人顺嘴说出来的话特别能暴露大家内心其实都很清楚政治环境是怎样的——“真民选就是爽 大家爱才是真的爱”(网友评《哪吒2》)。
铜仁女啊!啊!
boosted

Mark Zuckerberg 下载上亿本盗版电子书训练人工智能,身价百亿;Aaron Schwartz 下载几十万学术文章打算免费公开,被告到自杀。
钩诛国侯啊
铜仁女啊!啊!
boosted

铜仁女啊!啊!
boosted

如果你反对“DEI”,那么你应该直接说出完整的词,而不是只用缩写。要勇敢地说:“我反对多元化、公平和包容。” 如果你能坦诚地说出自己不喜欢哪一部分,那就更好了。 把它变成缩写只会让它成为一个终结思考的陈词滥调。 从现在开始,勇敢表达你的观点,但要具体。让所有人都知道,你到底是反对多元化,还是公平,还是包容? x.com/muqjm0t7kwtm...
幕府将军真的是一部拍得很日本但是一看就知道不是日本人拍的东西(好看的)
铜仁女啊!啊!
boosted

我已经很爱国了,我爱国的程度已经超出了国爱我的程度,已经是在倒贴了,还要我怎样
想了想好几个白板整理软件,最后因为boardmix太贵,返璞归真回到onenote……(主要是拿来做项目灵感整理)
哦发现买终身兑换码是四百出头,国区买的兑换码可以用在国际区账号吗(?
继续断舍离!!!!
好羡慕别人的精力啊啊啊。。。。

铜仁女啊!啊!
boosted

哪吒2还能拿影史票房只能说这个春节档是真的没有好一点的电影了。。。(
铜仁女啊!啊!
boosted

新生代女歌手我觉得最boring的就是娅,她哪来这么多死忠粉啊大家都一副没听过好的样子
铜仁女啊!啊!
boosted

读到一篇关于DeepSeek胡编乱造且嘴硬的文章 http://mp.weixin.qq.com/s/g37_UtaPpmuqQHnmSX8FCg 。读完觉得标题有点过于耸人听闻。在技术层面上,DeepSeek的胡编乱造/hallucination可能跟ChatGPT差不多(以前写过一条关于LLM AI的胡编不是bug而是feature的 https://bgme.me/@phyllisluna/112972829738698528 ,这里不展开了),甚至“嘴硬”可能也差不多。
觉得比较有意思的是DeepSeek(无意识/unintentional)精准抓住了国内人的认知过程弱点:在文中的例子里,DeepSeek瞎编的文献是政府文书/规范,恰恰是人们最容易闭眼信的——一方面是强权洗礼带来的畏惧,另一方面(paradoxically)是知道这些文件本身常常是nonsense的。另外,在这个具体的例子里,DeepSeek还(也是无意识)精准抓住了国内人对文物保护的盲信(e.g.时不时就冒出来关于文物拍照的掐架)。
原文作者强调的信息污染和认知陷阱(“比ChatGPT危险100倍”),我倒觉得不是全新的危机,毕竟看似客观真实信息的false information早在计算机出现之前就大量存在了,manipulation的历史大概跟人类历史本身一样古老(以前写过一条 https://bgme.me/@phyllisluna/113374456313207219 ,这里不展开了)。
关于的DeepSeek这个例子和过去ChatGPT的对比倒是给了我一个新想法:LLM AI本身是不会“思考”的,而是综合/平均/重组它的语料库/training set。正是这个特质让我们有机会去“聚焦”并反向trace到活人提供的语料库里的偏见和各种倾向。DeepSeek的胡编+似是而非论证方式恰恰在某种程度上反映了语料库里(当地/local)活人们试图组织一个论证以说服他人的方式(e.g.文物保护,政府公文)。而DeepSeek和ChatGPT在胡编上的差异或许又折射出了cultural/societal差异。
铜仁女啊!啊!
boosted

@nomikomu @savemoney @board 这位朋友 提醒一下 拼多多的迪卡侬是假货
铜仁女啊!啊!
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
有个事情,简单说是discord的聊天记录可能被泄露了。想提醒一下fedi里注意信息安全的各位。如果要转出,截图不要把我ID截进去
(以下内容整理自友邻带锁帖,最初发现的人也不是相关专业的,我也不是,只能是发现有这样的事情提醒注意一下,没深入探究。如果fedi网友有新发现请补充)
面向国际市场的中国产ai聊天app“meco”(中国区不能用),被发现能读取Telegram非加密聊天和Discord的聊天记录,方法是让它描述 discord.com/users/id 这个人和自己的关系。发现的网友试了两三个朋友的号,都有显示聊天记录,有tele和discord同名的,telegram记录也泄露了。涉及的聊天记录都截止至几个月前,推测是在ai训练过程中就已经加入。
telegram已经有几次被曝出卖用户信息的事,不过discord记录一模一样还很少听到。有可能是调用的那个基础模型爬过discord,或者discord和reddit一样把数据卖给某家大厂了。不能确定他们用的哪个base model。也没能多试几个discord号。
发出来也就是提醒一下在意的人。大家以后聊天留意一下,吧。
我走向你像走向一条河流
Joined May 2022
