
今晚本来想写GPT 4o的技术解答文章的不过有点迟了写到哪儿算哪儿,剩下的后面找时间继续写!
首先可能很多朋友只刷到过特别火也争议特别大的那个吉卜力风格化,但这其实不是什么新鲜的玩法了,只不过在效果上又更进一步。更加值得关注的其实是这次GPT-4o出了超多特别惊人的技术,基本上可以说是GPT本T长了手能画画了,不再存在GPT生成prompt命令呼叫 DALLE3导致的信息损耗了。(最开始GPT还不会自己画图的时候,是通过调用文生图大模型DALLE3来画图的,而不是它本身能产生图片)
例如它可以写非常非常长的文字(图一)
例如给定风格参考图让它画一个类似的海报(图二)
例如直接通过对话修改图片(图三)
例如画一些漫画或者插画(图四)
更多例子:
https://openai.com/index/introducing-4o-image-generation/
以上这些例子,都可以从各种意义上体现出,GPT模型自己长了个会画画的手,比调用另一个绘图模型在使用上有多大的变革。
比如说制造抹茶那个四格,如果是之前的流程,可能需要先让GPT生成抹茶做法的四个步骤,然后再让它把步骤转换成文生图模型的prompt,再调用DALLE3把图片画出来。每一个步骤都可能有损耗,尤其是最后一步,DALLE3可能没办法有这么好的文本对应性能精准画出这样的内容。但是GPT如果本来就会画画,事情就会变得很自然了。我们都知道GPT内部肯定是已经有关于如何制作抹茶的知识的,不止如此,GPT 4o还是一个多模态大模型。多模态的意思是它能够理解各种形式的信息,例如文字、图片、语言等。所以它同样也见过大量的“如何制作xx“这样的海报。于是它就可以直接结合这些知识生成图四这个结果。
又例如图二给定参考图来画新的图和用对话编辑图片也是非常自然。原本如果要做这些,用过SD系列工具的人会知道,你需要有一个实现这些功能的workflow,把各种模块组合在一起,让这些参考图以各种形式注入信息到模型,然后diffusion模型再接受这些信息作为生成图片的条件去完成指令。但其实diffusion原生是不支持这些编辑功能的,所以每个功能都需要单独作为一个任务去训练优化。但是其实这些任务本质上都是差不多的,只不过diffusion没有auto regressive model这样一切皆可tokenized的flexibility(这部分技术后面再解释)。所以GPT一旦能够生成高质量的图片,这些图片编辑操作能做得比diffusion模型好是非常自然而然水到渠成的事情。
OpenAI在做GPT 3.5(也就是最初的ChatGPT)的时候就很喜欢这种大一统的路线,在大家都在做专用模型(翻译模型、打分模型、聊天机器人等)的时候坚持做通用模型(一个模型解决所有任务),在diffusion风头正盛的时候坚持用自回归生成图片(DALLE3是先把图片tokenized后再用transformer生成的)之所以这么坚持就是为了有一天把文字和图片的token统一到一起。
编辑:最后一段我的记忆出现错误了。我重新核查了一下,dalle1是基于自回归的,dalle2论文里尝试了自回归和扩散两个方案,后者胜出,dalle3就是完全基于ldm了,应该是openai内部一直没有放弃自回归路线吧。
那么GPT 4o是如何做到的呢?接下来我说的是我结合社区讨论的一些猜想,不代表实际使用的技术。
首先是以CloseAI著称的OpenAI依然几乎没有透露任何技术细节,只说了新模型是基于自回归(auto-regression)的。
>The system uses an autoregressive approach — generating images sequentially from left to right and top to bottom, similar to how text is written — rather than the diffusion model technique used by most image generators (like DALL-E) that create the entire image at once. Goh speculates that this technical difference could be what gives Images in ChatGPT better text rendering and binding capabilities.
(https://www.theverge.com/openai/635118/chatgpt-sora-ai-image-generation-chatgpt)
另外在上面图一那张板书上写了“compose autoregressive prior with a powerful decoder”,右下角也写了tokens->[transformer]->[diffusion] pixels。所以现在社区上最主流的推测是使用了基于transformer的自回归架构,配合强大的diffusion decoder,达到的现在的效果。
前面说了多模态大模型的优势,现在讲讲如何达到支持多模态的训练。首先解释一下自回归,自回归被大量用于文字领域,因为它说白了就是一个接龙的过程。自回归模型把生成内容看成一系列无法穷举但是有固定范围的序列,这个序列可以是固定长度的也可以是不固定的,每次生成的时候会输入之前的所有结果。例如“你是谁?”模型在回答的时候就会先预测第一个字“我”,然后输入变成了“你是谁?我”,模型会认为下一个字大概率是“是”,之后再给模型输入“你是谁?我是”以此类推,一直到模型认为可以结束了,就会输出一个[END]的标记。遇到这个标记就可以停止继续生成了。
这个自回归模型被大量用在文字上,因为文字非常天然地符合自回归生成的逻辑。自回归模型的经典架构就是transformer,因为transformer对于较长的输入有着比之前的算法更优的计算方式(注意力机制,这个以后有机会再解释),所以在transformer问世之后在NLP领域嘎嘎乱杀一直到现在大语言模型发展得如此迅猛。
但是主流的文生图模型并不是基于自回归架构的,而是扩散模型。扩散模型是一种非自回归模型(Non Auto-Regressive Generation,NAR),它的图片是一次性生成全图再逐渐细化。
当然openAI早在2020年就尝试过了自回归生成图片:
https://openai.com/index/image-gpt/ 就是逐行生成图片的,只不过效果被扩散模型超越。自回归方式生成图片遇到的第一个问题就是,图片的可能性太多了。
自回归里有一个重要的概念叫token,就是GPT里按token收费的那个token。所有的tokens组成codebook,这个codebook也不能太大,越大计算量就越大。自回归本质上是token接龙,比如在中文里,每个中文汉字可以是一个token,因为汉字的数量是有限的。在英文里,英文单词也可以是一个token,不过实际上是用词根作为token,因为英文随时会出现新造的单词,这些单词依然可以用已有的词根组成。可以看到,文字是很好tokenized的,这也是自回归在语言模型被广泛使用的原因之一。
这里是一个token可视化的在线工具的分析结果:https://tiktoken.aigc2d.com/
所以基于自回归的多模态大模型,本质上依然也是这些token接龙,只不过多模态支持图像,声音等作为输入、输出,那就必须要把这些媒介也转换成可穷举的tokens。
下文继续说如何把图片转换成token。
所以基于自回归的多模态大模型,本质上依然也是这些token接龙,只不过多模态支持图像,声音等作为输入、输出,那就必须要把这些媒介也转换成可穷举的tokens。
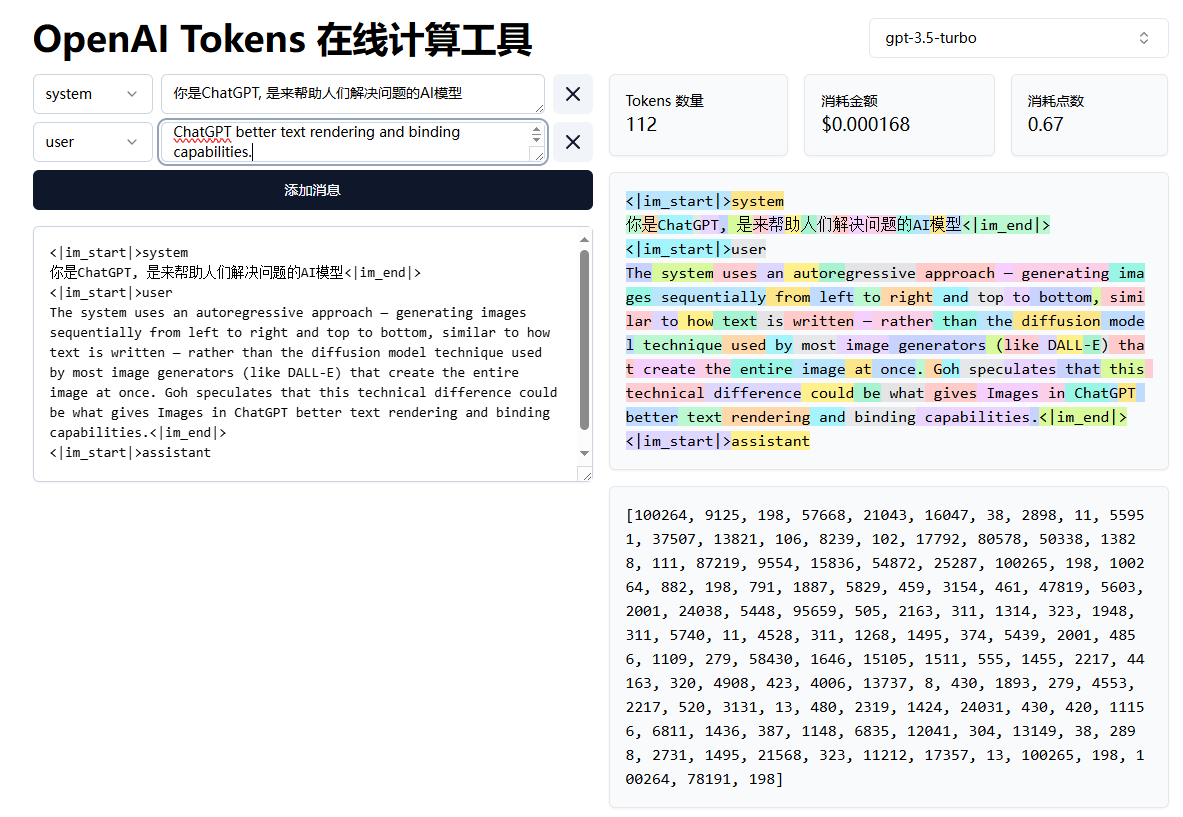
直接拿像素点作为token可行吗?一个像素有RGB三个通道,每个通道有0~255个取值,一共就是255^3 种可能,是可以穷举的。但是这样的话生成速度太慢了。一张1024* 1024的图相当于一段一百万字的文章(假设一个字是一个token)。于是很自然地,大家想到了使用auto-encoder对图像进行压缩。
有了auto-encoder以后就可以把压缩后的token拿去训练自回归网络,然后让自回归网络做token接龙,再拿decoder把token转换回图片了。
以上就是自回归网络如何生成图片的解释,晚点给大家解释什么叫强大的diffusion decoder。
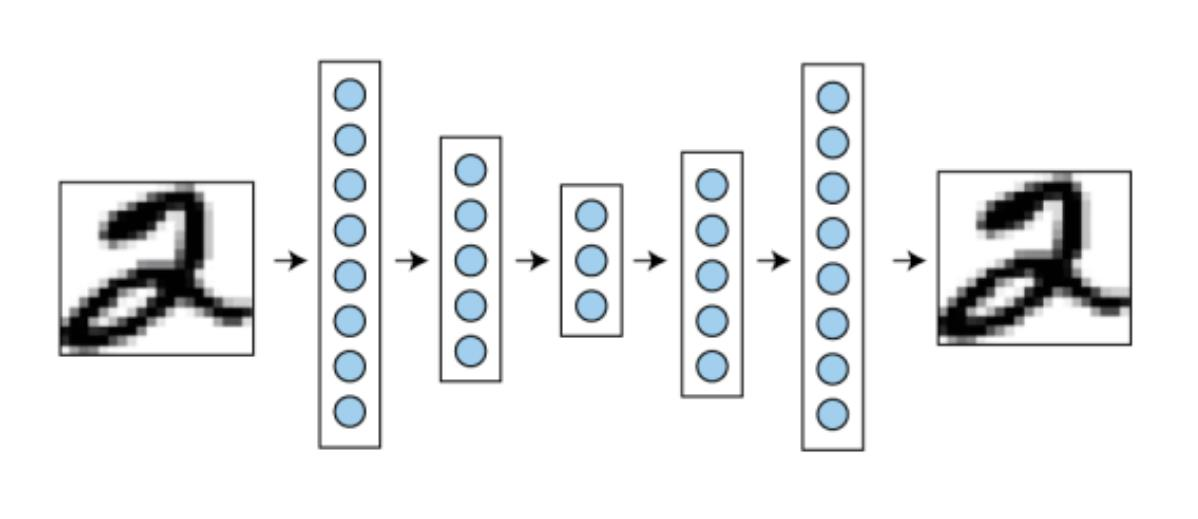
提到Auto-encoder一定会第一个想到VAE(以前写过的VAE和GAN的科普文章:https://blog.konata.vip/?p=248 )。VAE就是一个基于卷积的对称的压缩-解码结构,它可以把图片压缩到一个非常小的空间上(latent space)然后再解压缩还原为原图。知名的stable diffusion(和绝大部分主流文生图模型)就有使用VAE来先把图片进行压缩,再在latent维度上做去噪。(见图一)
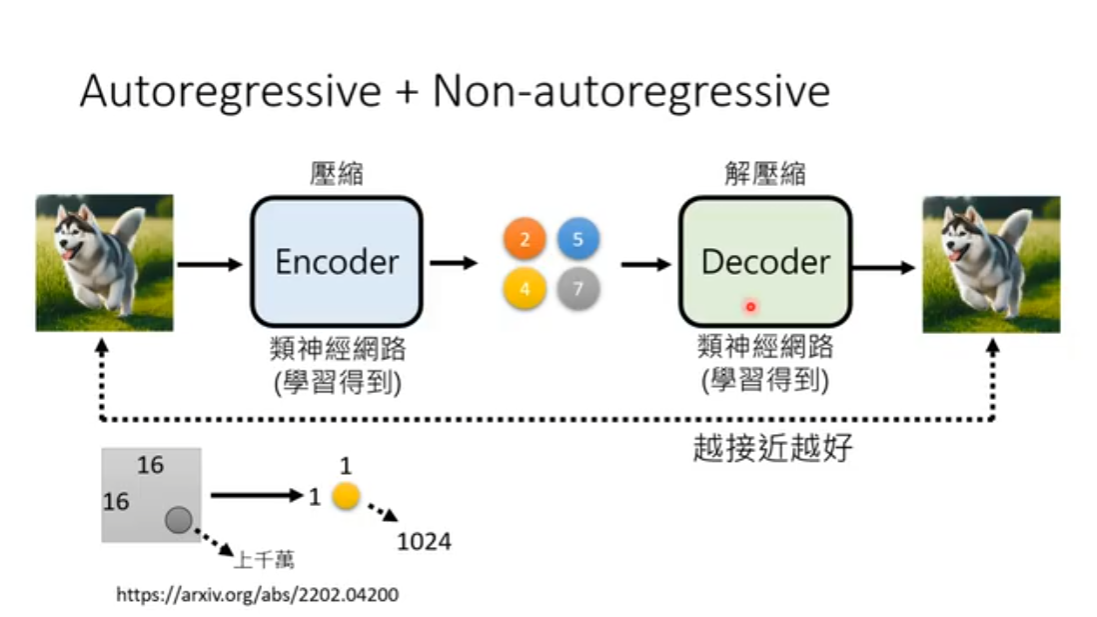
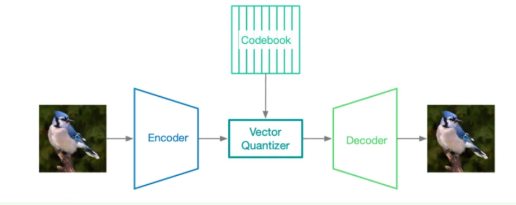
自回归和diffusion model使用的VAE不一样的地方在于,自回归的codebook大小是有限的,而VAE的latent space是连续的,所以会多出一个离散化(量化)的步骤,也就是VQ-VAE。这里的VQ就是vector quantization,向量量化。(见图二)
但是如果把一张图片的latent vector对应到codebook里的一个token,很明显decoder的信息量是不够的,因为把信息压缩得太极限了。所以通常会把图片切为一个个小格(patch),这样就够用了,这个操作的名字叫patchify。
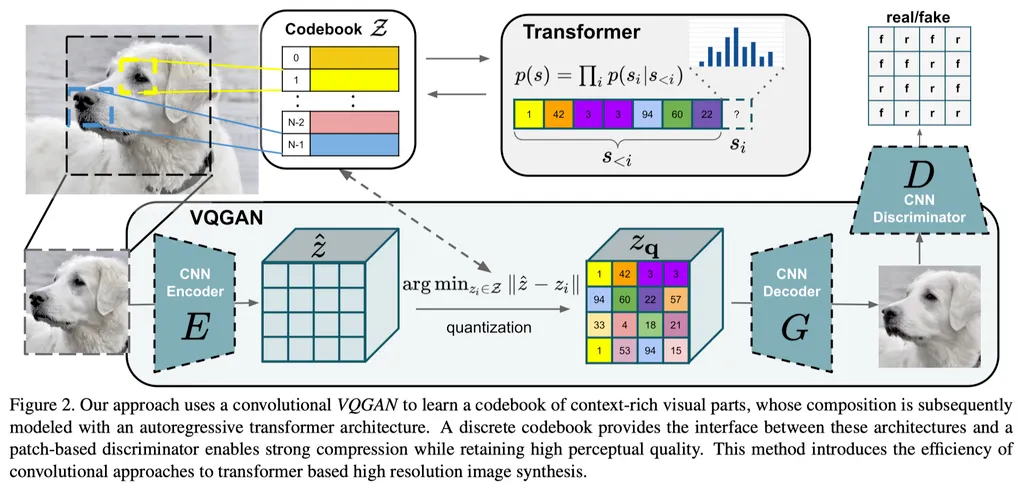
接下来的路线搞CV的应该很熟悉。可以看出来图像tokenize有两个最重要的指标,一个是图片压缩度,一个是图片还原度。而还原图片的质量和Decoder的能力是强相关的。VAE在图像生成上有各种硬伤,例如图片会趋向于模糊。于是很自然地,大家就想到增加对抗loss来提升效果,这就是VQ-GAN。(见图三)
可以看到从结构上主要是比VQ-VAE多了一个判别器,同时训练上也使用了GAN常用的感知损失代替VAE的像素级损失(如MSE),可以简单理解为前者对比的是生成数据和训练数据更高层级的特征对应性(通过预训练的神经网络提取特征),后者则是简单计算两张图片的距离(每个像素之间差多少)。
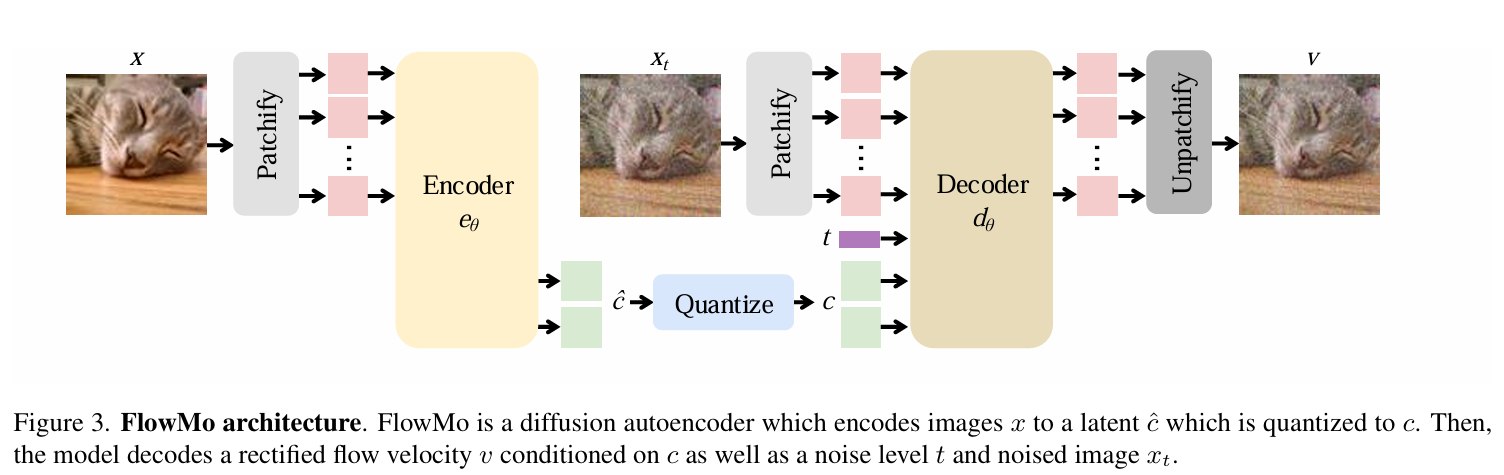
所以按照这个发展脉络,接下来就该轮到diffusion model出场了。李飞飞团队出了一篇新的paper叫Flow to the Mode(感觉在玩fly me to the moon的梗),简称FlowMo,就是采用了目前最流行的MMDiT(多模态transformer结构的扩散模型)和Rectified flow(比传统扩散模型更高效的一种“走直线”的生成方式)的方法训练Decoder。(见图四)
FlowMo在训练时分为了两个阶段,第一个阶段Decoder只做一步去噪,训练好Encoder、VQ、Decoder后,第二个阶段还会固定Encoder,单独对Decoder在8步去噪上进一步训练,以提升Decoder的生成效果。这个方法也在图像压缩上取得了目前最好的效果,也就是可以在最少的信息量(BPP,Bits per Pixel)上最好地还原图片。当然我想耗时肯定也是比之前的方法慢很多的,GPT 4o的图像生成确实是慢一些,不过相比带来的好处,这点耗时也是可以接受的。
有了这类更强力的图像tokenization和训练策略的提升,最后的结果就是GPT 4o一旦训练好,在图像生成、控制、编辑、语义理解等维度超出现有方法很多很多,并且是一个通用模型而不是专家模型(只专精于特定任务)。自回归做图像生成并不是一个很新鲜的事情,但由于训练困难、生成较慢被扩散模型取代。但是扩散模型很难像自回归模型这样做一个很完整的通用模型,每个任务都有专门的方法去进行适配,并且图文之间的信息交互也会有损失。GPT 3.5(第一代ChatGPT)相比于GPT 3在模型架构上并没有非常明显的改进,但是通过极大扩充训练集、参数量,增加大量的人类标注做SFT和强化学习,在性能上就立刻把模型提升到非常可用的高度。我想GPT 4o应该也是类似的技术路线,相比简单易懂的原理,效果的提升更重要的还是依赖背后的工程和训练方法。
应要求补充一下自回归训练部分,我真是有求必应啊!
以Emu3为例,我们来看看基于自回归的多模态大模型有哪些特殊之处。
Emu3是一个纯粹基于自回归预测下一个token,把图像、文本和视频编码为同一个离散空间训练的多模态大模型。和纯文本LLM相比,它的codebook除了文本token还包含了视觉token(基于SBER-MoVQGAN),为了统一格式,使用了如下的特殊标记:
```
[BOS]{文本}[SOV]{元数据}[SOT]{视觉tokens}[EOV][EOS]
```
- [BOS]和[EOS]是文本的开始和结束符号
- [SOV]和[EOV]是视觉输入的开始和结束符号
- [SOT]是视觉tokens的开始符号
通过这样的结构,纯文本数据和图文数据对(图片+caption)都可以统一输入给模型训练。
然后是训练策略,这部分和纯文本LLM比较相似。让我们先回顾一下ChatGPT为首的LLM训练流程:
1. 预训练阶段:也就是准备海量的数据让模型看,提供丰富的前置知识。此时模型只会模仿人类的数据,例如你问模型“世界上最高的山峰是什么?”模型有可能会输出:“A,阿尔卑斯山,B,珠穆朗玛峰……)因为它也有见过这样的数据,在和人类需求做对齐(alignment)之前,它不能理解你要它干什么,只是一味模仿。
2. 监督微调阶段:也就是使用一些高质量的人类标记数据,让模型的输出方式更符合我们的使用习惯,在ChatGPT里,就是使用GPT 3在一些问答数据上微调。例如给他”[用户]:“世界上最高的山峰是什么?[模型]:珠穆朗玛峰。“这些数据以后,它可能就可以理解自己需要给用户答案。
3. 强化学习阶段:经过SFT以后模型已经可以有一个能回答人类问题的语言模型了,此时可以让人类对模型的答案进行打分,让模型学习生成更能让人类满意的答案,这就是大名鼎鼎的RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。
在Emu3也有类似的几个阶段:
1. 预训练阶段:准备大量的文本、图片、视频资料进行训练,其中先使用文本和图片训练,再加入视频数据。
2. 质量微调阶段:使用高质量数据进行微调,如更高筛选标准和更高分辨率的优质图片。
3. DPO强化学习阶段:使用SFT模型生成多个结果,通过人类打分作为反馈进行强化训练,打分的重点在于生成质量和文本对齐程度。
从这个论文的效果来看,自回归生成图片的结果也是潜力很大的,不过这篇论文没有在图像编辑、风格转换等图像领域常见的任务上做训练和评测,猜想GPT-4o应该增加了不少这类任务的SFT数据去做对齐。这类训练数据可以通过从一些专家模型中蒸馏、人工PS等方式制造,再使用多模态视觉理解模型(相比生图模型较为成熟的一项技术)去打分筛选数据。大致流程可以参考这篇[OmniEdit](https://arxiv.org/pdf/2411.07199)
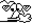
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

@ChuckL 都可以!